#1.爬取网页 def getData(baseurl): datalist=[] for i in range(0,10): url=baseurl+str(i*25) # 1.1爬取 html=askUrl(url) bs=BeautifulSoup(html,"html.parser") bss=bs.find_all("div",class_="item") # print(bss) # 1.2逐一解析数据 for item in bss: data=[] item=str(item)
name=re.findall(findname,item) if (len(name)==2): cname=name[0] oname=name[1] name=cname+oname data.append(name) else: data.append(name)
head={ "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:65.0) Gecko/20100101 Firefox/65.0"
} req=urllib.request.Request(url,headers=head) html=urllib.request.urlopen(req) return html
5.保存数据(以下方法二选一)
5.1.保存到excel
1 2 3 4 5 6 7 8 9 10 11 12 13
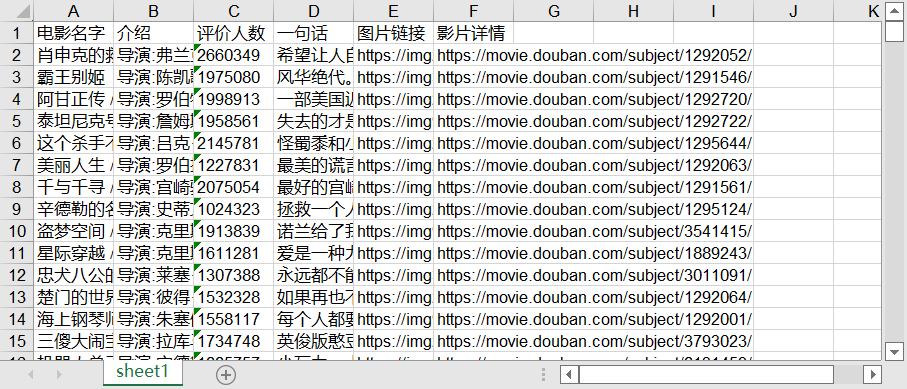
#3.保存数据到excel def saveData(datalist,savepath): addxls=xlwt.Workbook(encoding="utf-8") addsheet=addxls.add_sheet('sheet1') col=('电影名字','介绍','评价人数','一句话','图片链接','影片详情') for i in range(0,6): addsheet.write(0,i,col[i]) for i in range(0,250): data=datalist[i] print("第%d条"%i) for j in range(0,6): addsheet.write(i+1,j,data[j]) addxls.save(savepath)